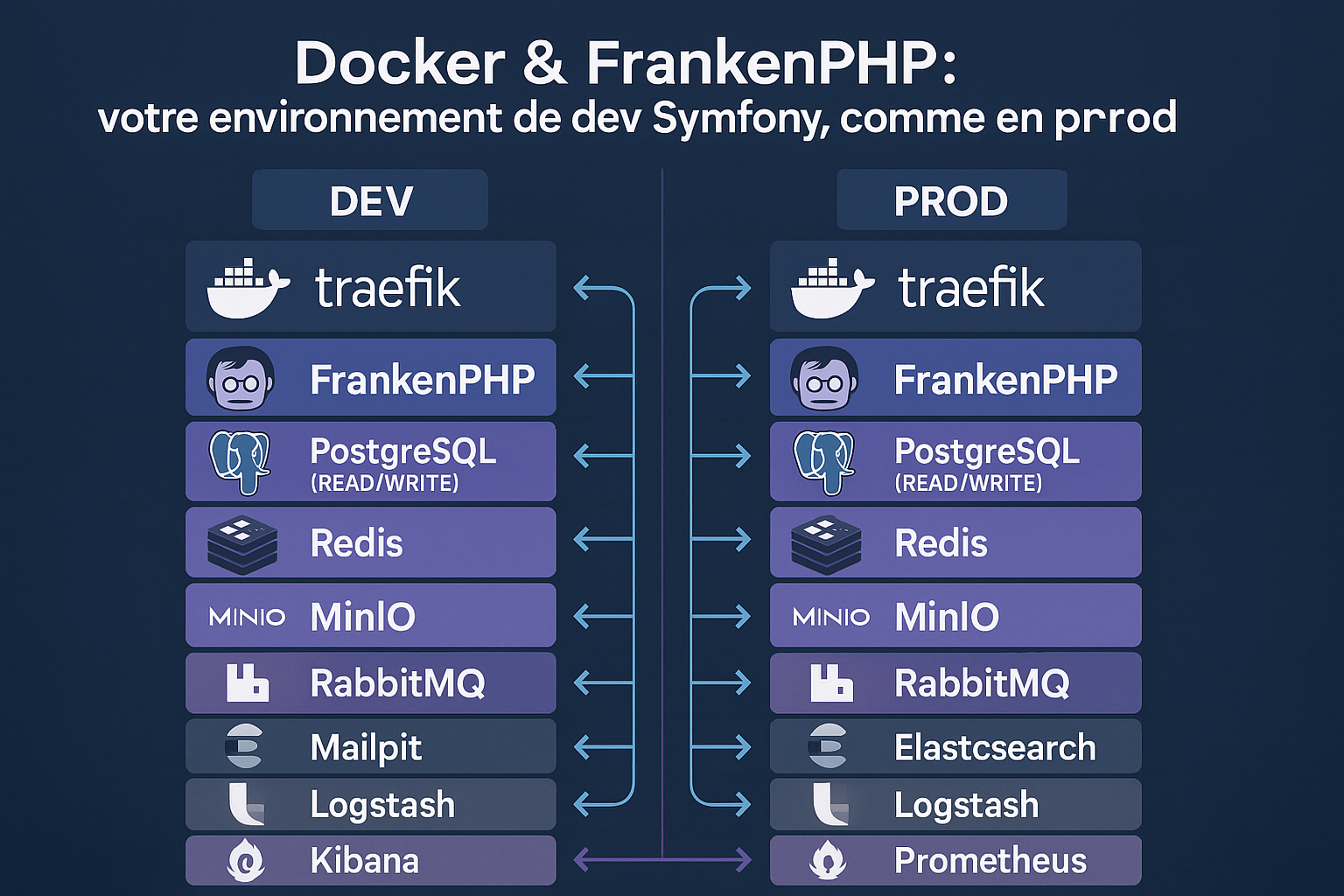
Introduction
Eh bien, nous y voilà : la partie 2 de notre exploration de Docker !
Encore une fois, je trouve cet outil extrêmement puissant, tant par sa rapidité d’usage que par la versatilité presque infinie qu’il offre.
Côté environnement, oui, c’est clairement overkill pour un simple projet local… mais ce n’est pas grave.
👉 Le but ici est d’apprendre, de comprendre les bonnes pratiques et surtout de poser les bases solides d’un futur déploiement en production.
Grâce à cette approche, nous allons pouvoir continuer à développer sereinement, sans craindre les problèmes d’environnement futurs.
Parce qu’aujourd’hui, on ne se contente pas de « faire tourner un projet » : on construit une vraie architecture complète, robuste, et prête pour la prod.
L’environnement extreme et scalable
J’ai décidé d’aller très loin pour cet environnement.
Nous commençons avec un load balancer (Traefik) et deux instances de FrankenPHP.
👉 Rien que ça, c’est déjà énorme en termes de performances, surtout sachant que les deux instances fonctionnent en mode Worker, pour tirer un maximum de rapidité.
Et ce n’est que le début…
Nous intégrons également :
- Deux bases de données PostgreSQL :
- Une dédiée aux écritures (Write)
- Une optimisée pour la lecture seule (Read)
(On reviendra en détail sur cette configuration plus loin.)
- Redis pour accélérer les lectures et optimiser la gestion du cache.
- RabbitMQ pour gérer l’envoi des e-mails, SMS, et tout traitement asynchrone, garantissant une haute résilience même sous forte charge.
- ElasticSearch pour indexer et rechercher efficacement les données.
- Grafana + Prometheus pour monitorer en temps réel toutes les métriques de notre projet, avec des dashboards prêts à l’emploi.
- MinIO, un stockage compatible S3, pour gérer les médias et les fichiers de manière performante et scalable.
Et là, vous vous dites peut-être :
« Mais qu’est-ce que c’est que cette architecture 3.0 ? »
Eh bien, tout simplement : un environnement complet, moderne, conçu pour la haute disponibilité et taillé pour absorber un trafic massif.
Bases de données READ / WRITE : pourquoi séparer ? 🛢️
En continuant mon exploration des architectures modernes, je me suis rendu compte d’une chose essentielle :
dans la plupart des projets web, il y a bien plus de lectures que d’écritures.
👉 Vous voyez le truc ?
Alors pourquoi ne pas séparer ces deux types d’opérations ?
C’est exactement ce que nous faisons ici, en créant :
- Une instance WRITE dédiée aux écritures,
- Une instance READ optimisée uniquement pour la lecture.
Et le plus beau dans tout ça ?
Symfony sait parfaitement gérer cette architecture nativement grâce à Doctrine — il suffit de configurer correctement vos connections !
Pourquoi cette approche est intelligente ?
On respecte le fonctionnement stateful des bases de données, en les spécialisant.
On évite de surcharger une seule base de données avec des accès concurrents lecture/écriture.
On optimise les performances en isolant les flux d’accès.
Et pour aller encore plus loin ?
Pour soutenir encore mieux la base de données et accélérer les lectures,
j’ai décidé d’ajouter Redis en tant que cache.
Résultat :
- Moins de requêtes SQL inutiles
- Temps de réponse ultra-rapide
- Moins de pression sur PostgreSQL
Mieux encore :
Dans des architectures de grande échelle, on pourrait imaginer plusieurs petites bases READ, chacune dédiée à une fonction spécifique (exemple : une base READ pour consulter les commandes, une autre pour les statistiques utilisateurs…).
Complexité ≠ complication, mais hiérarchie et anticipation
On pourrait se dire :
« Mais pourquoi se prendre autant la tête pour un simple environnement local ? »
Et la réponse est simple :
👉 Parce que ne pas le faire, c’est prendre un gros risque pour la suite.
Quand on décide d’introduire des éléments complexes dans une architecture — comme ici avec le split READ/WRITE, le cache Redis, ou le broker RabbitMQ — il vaut mieux les intégrer dès le début.
Sinon, on s’expose à :
- Des bugs de synchronisation difficiles à déboguer
- Des différences entre local et prod
- Des migrations douloureuses plus tard
Bref : plus on attend, plus c’est douloureux.
C’est pour cela que je choisis volontairement un setup ambitieux, même en dev local.
Il me permet d’avoir :
- Une architecture propre
- Facilement testable
- Futur-proof dès le premier commit
Mieux vaut une complexité hiérarchisée dès le départ, qu’un chaos non maîtrisé dans 6 mois. 😉
Load Balancer avec Traefik : une prod aux petits oignons⚡
On ne va pas rentrer ici dans tous les détails techniques de Traefik — l’outil est immense, robuste et capable de beaucoup de choses.
Mais ce qu’il faut retenir, c’est que Traefik est une valeur sûre pour gérer la répartition de charge et le routage dynamique dans une architecture Docker moderne.
🎯 Le principe de base
Traditionnellement, on a un serveur unique qui écoute sur un port (80 ou 443), et qui fait tout le travail lui-même.
Mais dès que la charge monte, tout explose.
Avec Traefik en reverse proxy et load balancer, on change complètement de paradigme :
- Traefik intercepte les requêtes entrantes
- Il les redirige vers le bon conteneur (app1, app2, etc.)
- Il peut aussi répartir la charge automatiquement entre plusieurs instances
👉 Résultat : une scalabilité horizontale fluide, automatique et maîtrisée.
🧱 L’importance de la séparation des services
Pour que tout fonctionne bien :
- Chaque application doit être stateless
- Chaque service doit être conteneurisé
- Les labels Traefik doivent être définis clairement
Ainsi, quelle que soit la charge ou le nombre d’utilisateurs, votre web app continue de tourner sans friction.
Et ce n’est que le début : avec Traefik, on peut y greffer fail2ban, des middlewares de sécurité, de l’auto-renouvellement SSL, voire une authentification OAuth.
C’est une bête de prod.



MinIO : idéal pour le stockage objet S3-compatible 🗃️
Quand on parle de stockage objet, on pense naturellement à AWS S3, la norme créée par Amazon.
Mais ici, on utilise MinIO : une alternative open-source, self-hosted, et totalement compatible S3.
On garde donc la logique AWS (WORM, buckets, politique d’accès…), mais sans dépendance au cloud, et en maîtrisant l’infrastructure.
🎯 Pourquoi utiliser MinIO dans cette architecture ?
- On peut stocker directement les images utilisateurs et fichiers dans MinIO,
plutôt que dans le dossierpublic/, ce qui garantit :- Une meilleure sécurité
- Une meilleure séparation des responsabilités
- Une scalabilité illimitée
- Les accès peuvent être sécurisés via des URLs temporisées ou des chaînes cryptées (SHA-256),
garantissant une lecture restreinte selon vos règles métiers. - Chaque bucket (l’équivalent d’un dossier racine) peut accueillir des pétaoctets de données — on est prêt pour la montée en charge.
- Il est possible de répliquer les données sur plusieurs instances MinIO,
comme un RAID 1, pour la tolérance de panne (en version simplifiée).
En résumé :
- Compatible S3
- Ultra-scalable
- 100 % maîtrisé
- Parfait pour du scale-as-you-grow
Bref, MinIO est une brique essentielle dans une architecture moderne où les données ne sont plus stockées en dur sur le serveur web.
Envoyer 1000 mails sans crash 📨
Eh oui, on l’oublie souvent…
Mais les e-mails, les SMS, les appels API, les traitements HTTP longs ou les rollbacks,
👉 ce sont de vrais points de fragilité dans une application web moderne.
Tant qu’on a 100 utilisateurs par heure, tout va bien.
Mais imaginez Amazon pendant le Prime Day :
Des milliers de requêtes simultanées, des envois massifs d’e-mails…
🔥 Là, il faut du solide.
La solution : l’asynchrone, avec RabbitMQ
C’est pourquoi on intègre ici RabbitMQ, un message broker ultra fiable, reconnu, et compatible avec le composant Messenger de Symfony.
Le principe est simple :
- Une tâche (comme un envoi d’e-mail ou une API externe) est mise dans une queue
- Elle sera traitée en arrière-plan par un worker, sans bloquer la requête utilisateur
Ce qu’on peut faire très facilement :
- Envoyer des e-mails en différé avec Symfony Mailer
- Déclencher des événements métiers asynchrones
- Piloter un scheduler ou déclencher des traitements internes conditionnels
- Gérer les priorités, les retry, les échecs, les logs… grâce aux files
L’asynchrone ne veut pas dire unidirectionnel :
RabbitMQ peut aussi déclencher des actions internes à votre projet en fonction des messages reçus.
Et ça, c’est magique.
Bientôt un article complet !
Je prépare un article dédié à RabbitMQ, avec deux cas concrets pour comprendre comment l’intégrer à vos projets Symfony de manière optimale.
Redis : la vitesse, rien que ça ⚡
Le cache, c’est bien.
Mais un cache mémoire ultra-performant, c’est encore mieux.
Sur ce blog, j’ai déjà évoqué l’utilisation de Redis pour la mise en cache d’articles.
Mais reprenons depuis le début avec un exemple très parlant.
Cas pratique : l’enfer des relations
Imaginez une application qui doit afficher les relations entre utilisateurs et produits.
Si chaque utilisateur est lié à 1000 produits, chaque affichage peut rapidement devenir un cauchemar en lecture SQL,
👉 même avec une base PostgreSQL optimisée en READ.
Résultat :
- Des dizaines de requêtes
- Des temps de réponse qui explosent
- Une UX qui s’effondre
🚀 Redis à la rescousse
Redis, c’est :
- Un cache mémoire ultra-rapide
- Capable de gérer ses propres écritures
- Facilement purgeable, warmable, observable
Et les résultats sont bluffants :
Passer de 10 requêtes SQL à 0, et de 45ms à 1ms pour les mêmes données.
Oui, vous avez bien lu.
À savoir :
Redis fonctionne en RAM, donc ça consomme de la mémoire vive.
Mais pour certaines fonctionnalités critiques, c’est un investissement qui change la donne.
Exemple d’architecture combinée
On peut même aller plus loin :
- Une queue RabbitMQ déclenche une commande Symfony
- Cette commande purge ou met à jour dynamiquement le cache Redis
- Résultat : un système synchronisé et intelligent
(ex : mise à jour de catalogue produits)
Pourquoi Redis est utile même dans un POC ?
Parce que Redis vous montre très tôt les limites de votre logique métier.
Et même si c’est overkill pour un petit projet, ça vous forme à penser performance et scalabilité dès le départ.
Logs & visibilité : observer son infra en self-host 🕵️♂️
Les logs serveur, les charges CPU, les erreurs HTTP, les requêtes lentes…
Ce sont toutes des données critiques qu’on doit observer pour anticiper les problèmes, comprendre les pics de charge et optimiser son infra.
Et pour ça, rien de tel que la stack ELK.
ELK : plus qu’un moteur de recherche
Quand on parle d’Elasticsearch, on pense souvent à un moteur de recherche puissant.
Mais en réalité, il est parfaitement adapté à la gestion de logs, surtout lorsqu’on l’intègre dans une stack ELK :
- Elasticsearch : stockage et indexation des données
- Logstash : ingestion, transformation et routage des logs
- Kibana : visualisation et dashboards en temps réel
Pourquoi intégrer ELK dans cette architecture ?
- Analyser les logs de vos conteneurs
- Repérer les erreurs critiques, les downtimes, les accès suspects
- Suivre le trafic et visualiser les erreurs HTTP
- Auditer des actions utilisateur (même anonymisées)
C’est une vraie trousse à outils DevOps, accessible, visuelle et hautement personnalisable.
ELK ≠ Prometheus/Grafana
Attention : ELK n’est pas redondant avec Grafana et Prometheus.
Ces outils sont complémentaires :
- Prometheus + Grafana : collecte de métriques (CPU, mémoire, requêtes/s)
- ELK : gestion et analyse de logs textuels structurés ou non
En clair :
- Grafana = chiffres
- Kibana = logs
Exemple concret
Avec ELK, on peut :
- Faire transiter des données utilisateurs anonymisées
- Générer des statistiques automatisées (ventes, usages, taux d’erreur)
- Explorer librement des logs JSON, CSV ou non structurés
Tout cela grâce à la souplesse de la structure de données Elasticsearch.

Docker Compose : la base de l’architecture
Chaque projet a des besoins spécifiques. L’architecture technique doit donc s’adapter à la logique métier, aux contraintes d’usage, et aux objectifs de performance.
C’est pourquoi je vous propose ici un exemple de docker-compose.yml complet, pensé comme un Proof of Concept (POC) solide, extensible et surtout… identique à ce qu’on déploierait en production.
# docker-compose.yml complet Symfony FrankenPHP
services:
# --- Reverse Proxy ---
loadbalancer:
image: traefik:v2.10
container_name: docker-learn-traefik
command:
- "--api.insecure=true"
- "--providers.docker=true"
- "--providers.docker.exposedbydefault=false"
- "--entrypoints.web.address=:80"
- "--log.level=DEBUG"
- "--providers.docker.network=app_network" # Réseau à surveiller
ports:
- "80:80"
- "8080:8080" # Dashboard Traefik
volumes:
- /var/run/docker.sock:/var/run/docker.sock:ro
- ./docker/traefik/traefik.yml:/etc/traefik/traefik.yml:ro # Chemin relatif correct depuis la racine
networks:
- app_network
deploy:
resources:
limits:
memory: 200m
logging: &logging_defaults # Alias YAML pour réutiliser la config de logging
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
# --- Applications Symfony/FrankenPHP ---
app1:
build:
context: . # Contexte de build est la racine du projet
dockerfile: docker/Dockerfile # Chemin vers le Dockerfile relatif au contexte
container_name: docker-learn-frankenphp1
labels:
- "traefik.enable=true"
- "traefik.http.routers.app1.rule=Host(`app1.localhost`)"
- "traefik.http.routers.app1.entrypoints=web"
- "traefik.http.services.app1.loadbalancer.server.port=80"
volumes:
- .:/app
- ./docker/php.ini:/usr/local/etc/php/conf.d/app.ini
- ./docker/Caddyfile:/etc/caddy/Caddyfile
- caddy_data:/data
- caddy_config:/config
- ./docker/certs:/etc/caddy/certs
environment:
- APP_ENV=dev
- APP_DEBUG=1
- DATABASE_URL=postgresql://user:password@db_write:5432/app?serverVersion=16
- DATABASE_READ_URL=postgresql://user:password@db_read:5432/app?serverVersion=16
- REDIS_URL=redis://redis:6379
- MAILER_DSN=smtp://mailserver:1025
- S3_ENDPOINT=http://minio:9000
- S3_ACCESS_KEY=${MINIO_ROOT_USER:-minioadmin}
- S3_SECRET_KEY=${MINIO_ROOT_PASSWORD:-minioadmin}
- S3_REGION=us-east-1
- S3_BUCKET=symfony
networks:
- app_network
depends_on:
- db_write
- db_read
- redis
- mailserver
- minio
deploy:
resources:
limits:
memory: 400m
logging: *logging_defaults # Utilise l'alias
app2:
build:
context: . # Contexte de build est la racine du projet
dockerfile: docker/Dockerfile # Chemin vers le Dockerfile relatif au contexte
container_name: docker-learn-frankenphp2
labels:
- "traefik.enable=true"
- "traefik.http.routers.app2.rule=Host(`app2.localhost`)"
- "traefik.http.routers.app2.entrypoints=web"
- "traefik.http.services.app2.loadbalancer.server.port=80"
volumes:
- .:/app
- ./docker/php.ini:/usr/local/etc/php/conf.d/app.ini
- ./docker/Caddyfile:/etc/caddy/Caddyfile
- caddy_data:/data
- caddy_config:/config
- ./docker/certs:/etc/caddy/certs
environment:
- APP_ENV=dev
- APP_DEBUG=1
- DATABASE_URL=postgresql://user:password@db_write:5432/app?serverVersion=16
- DATABASE_READ_URL=postgresql://user:password@db_read:5432/app?serverVersion=16
- REDIS_URL=redis://redis:6379
- MAILER_DSN=smtp://mailserver:1025
- S3_ENDPOINT=http://minio:9000
- S3_ACCESS_KEY=${MINIO_ROOT_USER:-minioadmin}
- S3_SECRET_KEY=${MINIO_ROOT_PASSWORD:-minioadmin}
- S3_REGION=us-east-1
- S3_BUCKET=symfony
networks:
- app_network
depends_on:
- db_write
- db_read
- redis
- mailserver
- minio
deploy:
resources:
limits:
memory: 400m
logging: *logging_defaults # Utilise l'alias
# --- Bases de Données PostgreSQL ---
db_write:
image: postgres:16-alpine
container_name: docker-learn-pg-primary
environment:
POSTGRES_USER: ${POSTGRES_USER:-user}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-password}
POSTGRES_DB: ${POSTGRES_DB:-app}
PGDATA: /var/lib/postgresql/data/pgdata
volumes:
- db_write_data:/var/lib/postgresql/data
- ./docker/postgres/primary:/docker-entrypoint-initdb.d # Chemin correct
- ./docker/postgres/postgresql-primary.conf:/etc/postgresql/postgresql.conf # Chemin correct
command: postgres -c config_file=/etc/postgresql/postgresql.conf
networks:
- app_network
ports:
- "5432:5432"
deploy:
resources:
limits:
memory: 500m
logging: *logging_defaults
db_read:
image: postgres:16-alpine
container_name: docker-learn-pg-replica
environment:
POSTGRES_USER: ${POSTGRES_USER:-user}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD:-password}
POSTGRES_DB: ${POSTGRES_DB:-app}
PGDATA: /var/lib/postgresql/data/pgdata
PRIMARY_HOST: db_write
PRIMARY_PORT: 5432
REPLICA_NAME: replica1
volumes:
- db_read_data:/var/lib/postgresql/data
- ./docker/postgres/replica:/docker-entrypoint-initdb.d # Chemin correct
- ./docker/postgres/postgresql-replica.conf:/etc/postgresql/postgresql.conf # Chemin correct
command: postgres -c config_file=/etc/postgresql/postgresql.conf
networks:
- app_network
ports:
- "5433:5432"
depends_on:
- db_write
deploy:
resources:
limits:
memory: 500m
logging: *logging_defaults
# --- Cache ---
redis:
image: redis:7.2-alpine
container_name: docker-learn-redis
volumes:
- redis_data:/data
networks:
- app_network
command: redis-server --appendonly yes --maxmemory 256mb --maxmemory-policy allkeys-lru
deploy:
resources:
limits:
memory: 300m
logging: *logging_defaults
# --- Stockage Objet ---
minio:
image: minio/minio
container_name: docker-learn-minio
environment:
MINIO_ROOT_USER: ${MINIO_ROOT_USER:-minioadmin}
MINIO_ROOT_PASSWORD: ${MINIO_ROOT_PASSWORD:-minioadmin}
volumes:
- minio_data:/data
command: server /data --console-address ":9001"
ports:
- "9000:9000"
- "9001:9001"
networks:
- app_network
deploy:
resources:
limits:
memory: 350m
logging: *logging_defaults
healthcheck:
test: ["CMD-SHELL", "curl -f http://localhost:9000/minio/health/ready || exit 1"]
interval: 30s
timeout: 20s
retries: 3
minio-init:
image: minio/mc
container_name: docker-learn-minio-init
depends_on:
minio:
condition: service_healthy
environment:
MINIO_ROOT_USER: ${MINIO_ROOT_USER:-minioadmin}
MINIO_ROOT_PASSWORD: ${MINIO_ROOT_PASSWORD:-minioadmin}
entrypoint: >
/bin/sh -c "
/usr/bin/mc config host add myminio http://minio:9000 $${MINIO_ROOT_USER} $${MINIO_ROOT_PASSWORD};
/usr/bin/mc mb myminio/symfony --ignore-existing;
/usr/bin/mc policy set public myminio/symfony;
exit 0;
"
networks:
- app_network
deploy:
resources:
limits:
memory: 100m
# --- Messagerie Asynchrone ---
rabbitmq:
image: rabbitmq:3.12-management-alpine
container_name: docker-learn-rabbitmq
hostname: rabbitmq
environment:
- RABBITMQ_DEFAULT_USER=${RABBITMQ_USER:-user}
- RABBITMQ_DEFAULT_PASS=${RABBITMQ_PASSWORD:-password}
- RABBITMQ_DEFAULT_VHOST=${RABBITMQ_VHOST:-/}
ports:
- "5672:5672"
- "15672:15672"
volumes:
- rabbitmq_data:/var/lib/rabbitmq
networks:
- app_network
deploy:
resources:
limits:
memory: 350m
healthcheck:
test: rabbitmq-diagnostics -q ping
interval: 10s
timeout: 5s
retries: 5
logging: *logging_defaults
# --- Serveur Mail (Test) ---
mailserver:
image: axllent/mailpit
container_name: docker-learn-mailpit
ports:
- "1025:1025"
- "8025:8025"
environment:
MP_SMTP_AUTH_ACCEPT_ANY: 1
MP_SMTP_AUTH_ALLOW_INSECURE: 1
networks:
- app_network
deploy:
resources:
limits:
memory: 100m
logging: *logging_defaults
# --- Stack ELK (Logging Centralisé) ---
elasticsearch:
image: elasticsearch:8.11.1
container_name: docker-learn-elasticsearch
environment:
- discovery.type=single-node
- xpack.security.enabled=false
- "ES_JAVA_OPTS=-Xms512m -Xmx1g"
- "cluster.routing.allocation.disk.threshold_enabled=true"
- "cluster.routing.allocation.disk.watermark.low=1gb"
- "cluster.routing.allocation.disk.watermark.high=500mb"
- "cluster.routing.allocation.disk.watermark.flood_stage=250mb"
- "thread_pool.write.queue_size=100"
volumes:
- elasticsearch_data:/usr/share/elasticsearch/data
ports:
- "9200:9200"
networks:
- app_network
deploy:
resources:
limits:
memory: 1g
ulimits:
memlock:
soft: -1
hard: -1
nofile:
soft: 65536
hard: 65536
logging: *logging_defaults
logstash:
image: logstash:8.11.1
container_name: docker-learn-logstash
volumes:
- ./docker/logstash/pipeline:/usr/share/logstash/pipeline:ro # Chemin correct
ports:
- "5044:5044"
- "9600:9600"
environment:
LS_JAVA_OPTS: "-Xms128m -Xmx256m"
networks:
- app_network
depends_on:
- elasticsearch
deploy:
resources:
limits:
memory: 350m
logging: *logging_defaults
kibana:
image: kibana:8.11.1
container_name: docker-learn-kibana
ports:
- "5601:5601"
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
- "NODE_OPTIONS=--max-old-space-size=256"
networks:
- app_network
depends_on:
- elasticsearch
deploy:
resources:
limits:
memory: 350m
logging: *logging_defaults
filebeat:
image: elastic/filebeat:8.11.1
container_name: docker-learn-filebeat
volumes:
- ./docker/filebeat/filebeat.yml:/usr/share/filebeat/filebeat.yml:ro # Chemin correct
- /var/lib/docker/containers:/var/lib/docker/containers:ro
- /var/run/docker.sock:/var/run/docker.sock:ro
user: root
networks:
- app_network
depends_on:
logstash:
condition: service_started
deploy:
resources:
limits:
memory: 200m
logging: *logging_defaults
# --- Outils d'Administration/Vérification ---
pgrepcheck:
image: postgres:16-alpine
container_name: docker-learn-pg-check
volumes:
- ./docker/scripts:/scripts # Chemin correct
entrypoint: /scripts/check-replication.sh
networks:
- app_network
depends_on:
db_write:
condition: service_started
db_read:
condition: service_started
restart: "no"
deploy:
resources:
limits:
memory: 100m
adminer:
image: adminer:latest
container_name: docker-learn-adminer
ports:
- "8081:8080"
environment:
- ADMINER_DEFAULT_SERVER=db_write
- ADMINER_DESIGN=flat
networks:
- app_network
depends_on:
- db_write
- db_read
deploy:
resources:
limits:
memory: 150m
logging: *logging_defaults
# --- Monitoring ---
prometheus:
image: prom/prometheus:v2.42.0
container_name: docker-learn-prometheus
volumes:
- ./docker/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml # Chemin correct
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
ports:
- "9090:9090"
networks:
- app_network
deploy:
resources:
limits:
memory: 300m
logging: *logging_defaults
grafana:
image: grafana/grafana:9.5.2
container_name: docker-learn-grafana
volumes:
- grafana_data:/var/lib/grafana
- ./docker/grafana/provisioning:/etc/grafana/provisioning # Chemin correct
environment:
- GF_SECURITY_ADMIN_USER=${GRAFANA_USER:-admin}
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_PASSWORD:-admin}
- GF_USERS_ALLOW_SIGN_UP=false
ports:
- "3000:3000"
networks:
- app_network
depends_on:
- prometheus
deploy:
resources:
limits:
memory: 256m
logging: *logging_defaults
# --- Réseau & Volumes ---
networks:
app_network:
name: app_network # Force le nom exact du réseau
driver: bridge
volumes:
db_write_data:
db_read_data:
redis_data:
elasticsearch_data:
prometheus_data:
grafana_data:
minio_data:
rabbitmq_data:
caddy_data:
caddy_config:⚙️ Ce que cette configuration contient :
- 🔀 Traefik en reverse proxy et load balancer intelligent
- 🧠 Deux instances FrankenPHP (Symfony) en worker mode
- 🗃️ PostgreSQL en double instance (READ / WRITE)
- ⚡ Redis en cache mémoire haute vitesse
- 📨 RabbitMQ pour la gestion des tâches asynchrones
- 🖼️ MinIO, un S3-compatible pour le stockage objet
- 📊 Prometheus + Grafana pour le monitoring
- 🕵️♂️ ELK Stack (Elasticsearch, Logstash, Kibana, Filebeat) pour centraliser les logs
- ✉️ Mailpit pour tester les e-mails
- 🛠️ Adminer pour gérer rapidement les bases de données
- 🧪 Des scripts de contrôle (réplication PostgreSQL, init MinIO, etc.)
Conclusion : trop… mais pas tant que ça 🚀
On vient de poser ici un POC complet, pensé pour reproduire une architecture de production en local.
Résultat : une stack scalable, puissante, capable d’encaisser de la charge, de gérer des traitements massifs, et même de stocker des données en WORM, façon AWS S3… mais en self-hosted.
🧠 Ce qu’il faut retenir :
- Ce n’est pas une solution unique mais une proposition inspirée de mes réflexions quotidiennes
- On n’est pas encore en production, mais déjà à un niveau pré-prod très avancé
- Oui, on pourrait aller encore plus loin (sécurité, CI/CD, HA…),
mais l’essentiel est là : une base solide, modulaire, extensible
❌ Pourquoi ce n’est pas encore “prod ready” ?
- Les conteneurs ont encore les droits root
- Le réseau entre les services doit être sécurisé et cloisonné
- Il manque des mécanismes de monitoring d’état avancés et de déploiement automatisé
Mais ce setup est idéal pour tout dev qui veut travailler comme en prod, tester des scénarios complexes, et préparer un futur déploiement sans surprise.
🙏 Et surtout, un immense merci à la communauté Open Source.
Grâce à elle, on a aujourd’hui accès à des outils puissants, gratuits, et professionnels, pour créer des environnements aussi robustes que ceux des grandes entreprises.
Je me suis bien amusé à monter tout ça — et j’espère que vous apprendrez autant en le testant que moi en le construisant.
Cet article t’a plu ?
J’ai beaucoup appris en faisant cet article aussi si jamais tu veux savoir pourquoi Turbo avec Symfony c’est un excellent combo ?
Laisser un commentaire