
Introduction
On poursuit notre aventure avec la V4 de notre classe virtuelle intelligente, toujours dans une logique incrémentale et concrète. Cette fois, on franchit une étape clé : l’intégration de LiveKit pour transformer notre environnement en une véritable plateforme de streaming souveraine — un Google Meet à la française, hébergé sur nos propres serveurs.
L’objectif ? Donner vie à une classe virtuelle immersive, où chaque professeur peut diffuser son cours en direct, tandis que les élèves interagissent en temps réel, que ce soit par le micro ou par message. L’école numérique prend ici une dimension beaucoup plus vivante et collaborative.
Côté intelligence artificielle, Rubix ML conserve sa place centrale, mais son rôle évolue. Au lieu d’analyser simplement des interactions individuelles, il devient un outil de scoring collectif, capable d’évaluer la dynamique globale de la classe. On ne parle plus seulement d’un élève noté par l’IA, mais d’une classe qui apprend, réagit et progresse ensemble.
Et bien sûr, on ne change pas une équipe qui gagne : tout cela repose toujours sur notre framework favori, Symfony, garant d’une architecture robuste, extensible et élégante.
LiveKit, le streaming 2.0
Le monde du streaming regorge d’outils, d’API et de solutions propriétaires plus ou moins ouvertes. Pourtant, au détour de mes expérimentations, je suis tombé sur une pépite open source : LiveKit. Dès la page d’accueil, on comprend le potentiel — la technologie est si solide qu’elle est utilisée par OpenAI pour la gestion du chat vocal en temps réel dans ses assistants. Rien que ça !
LiveKit, c’est un peu le chaînon manquant entre le streaming classique et l’intelligence artificielle temps réel. Entièrement open source, il s’intègre en un clin d’œil dans notre environnement grâce à un simple ajout dans le docker-compose.yml. Pas besoin de serveurs exotiques ni de licences hors de prix : tout tourne chez nous, avec une performance redoutable.
Mais le plus intéressant, c’est sa capacité d’intégration directe avec un LLM (Large Language Model). Autrement dit, LiveKit ne se contente pas de diffuser des flux vidéo et audio : il peut servir de passerelle entre le monde humain et celui de l’IA. On commence à voir se dessiner la suite : des cours diffusés en direct, une IA à l’écoute, capable d’analyser les échanges, d’évaluer les interactions, et même d’intervenir ou de modérer si besoin.
Avec LiveKit, on pose les fondations techniques d’une classe virtuelle réellement interactive, où chaque parole, chaque message devient un signal exploitable par notre pipeline d’analyse.
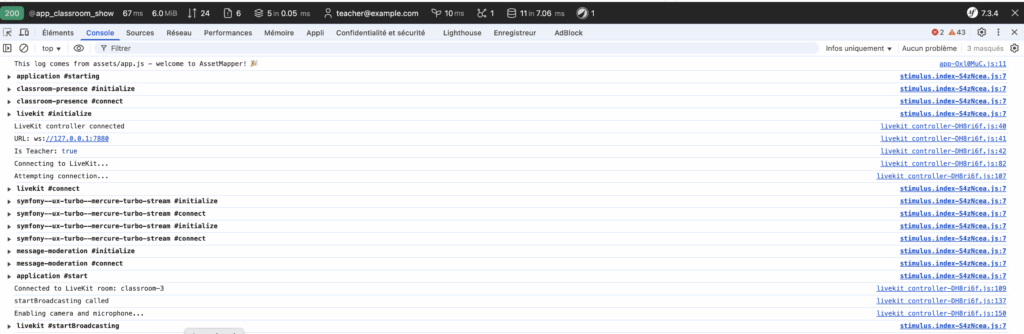
Lors de cette phase de test, la console confirme que la connexion entre Symfony et LiveKit s’établit correctement en local. Le contrôleur détecte le rôle de l’utilisateur — ici l’enseignant — puis initie la session vidéo en ouvrant une connexion WebSocket sur ws://127.0.0.1:7880. Une fois la salle “classroom-3” rejointe, la caméra et le micro sont activés automatiquement, déclenchant la diffusion en direct. En parallèle, les composants Symfony UX Turbo et Mercureassurent la synchronisation en temps réel du chat et de la modération, permettant à la classe virtuelle de réagir instantanément aux messages et aux interactions. Ce bloc illustre le bon fonctionnement de l’ensemble de la pile locale : LiveKit gère la visio, Symfony orchestre l’expérience et l’IA encadre le tout.
La suite du ML
Dans la continuité de nos précédents tests, on poursuit cette approche hybride entre le local et le cloud. L’idée est simple : combiner la puissance des modèles hébergés et la maîtrise de nos données locales. Pour cette V4, on introduit une brique essentielle : Whisper, le moteur de speech-to-text développé par OpenAI.
Whisper a une mission cruciale dans notre classe virtuelle : écouter, transcrire et structurer la parole en texte fiable, directement exploitable par notre pipeline d’analyse. Pendant le cours, chaque intervention vocale — qu’elle vienne du professeur ou d’un élève — est transformée en texte propre, synchronisé avec le flux LiveKit. Ces données, une fois correctement stockées, deviennent la matière première que Rubix ML va ingérer pour apprendre le comportement collectif de la classe.
C’est ici que la magie opère : on ne se contente plus de “noter” les élèves, on entraîne un modèle d’intelligence collective. Rubix ML observe les échanges, détecte des dynamiques, ajuste les pondérations, et affine en continu son interprétation. Un apprentissage récursif et contextuel, qui rend chaque session un peu plus intelligente que la précédente.
Et parce qu’on reste fidèles à notre philosophie d’intégration ouverte, on garde aussi un canal de fallback connecté à GPT5-nano — un modèle de langage plus large, capable de rattraper les cas ambigus, d’interpréter le ton, ou de qualifier le sens des échanges. Whisper nous livre les données brutes, Rubix ML les apprend, et GPT5-nano vient affiner la compréhension globale.
Résultat : une IA de classe capable de progresser d’elle-même, de reconnaître les schémas d’interaction et de s’adapter au rythme réel de l’apprentissage collectif. Une boucle fermée, vivante, presque organique — l’apprentissage récursif dans toute sa splendeur.
Les données, le problème
Qui dit Machine Learning, dit données. Et là, impossible d’y couper : la question du RGPD revient toujours frapper à la porte. Je suis particulièrement attentif à cela dans mes projets comme dans mon quotidien. Les données sont indispensables à l’entraînement d’un modèle, mais l’obsession du “Big Data” finira par être le talon d’Achille des géants du numérique.
(Et pour ceux qui en doutent, jetez un œil à ce que SORA 2 a déjà déclenché sur les réseaux : la prolifération des vidéos IA en est une preuve flagrante.)
Alors, comment concilier intelligence artificielle et respect de la vie privée ?
La réponse, c’est l’anonymisation. Que ce soit pour notre propre moteur Rubix ML ou pour les API tierces comme OpenAI, chaque donnée transmise doit être nettoyée de tout identifiant personnel. Le nom, le prénom, l’âge, la voix identifiable ou tout autre marqueur individuel doivent être neutralisés avant traitement.
Pourquoi ? Parce que dans notre contexte, ces informations n’ont aucune valeur analytique. Ce qui nous intéresse, ce n’est pas qui parle, mais comment la classe réagit, collabore, progresse. Nous faisons du scoring comportemental, pas de la surveillance.
Et c’est là un point crucial : aucun service ne devrait jamais décider à la place de l’utilisateur de l’usage de ses données personnelles — encore moins pour les revendre ou les exploiter à d’autres fins. Le futur du ML éthique passe par cette responsabilité : celle de préserver la confiance sans brider l’innovation.
PHP, c’est lent et nul ? Pas vraiment.
Soyons francs : PHP n’a jamais été conçu pour entraîner un modèle de langage géant. Ce n’est ni son ADN, ni son ambition. Mais dire que “PHP, c’est lent et nul” relève d’un cliché d’un autre temps. Car aujourd’hui, grâce à des outils comme Rubix ML et FrankenPHP, le langage peut parfaitement tenir sa place dans une architecture d’IA moderne.
Rubix ML, c’est justement la clé : une librairie de Machine Learning 100 % PHP, taillée pour des usages pragmatiques. Classification, régression, clustering, modèles supervisés ou non — elle couvre une large gamme de cas, et dispose même de transformers avancés pour les usages plus complexes. Autrement dit, pas besoin de réécrire son backend en Python pour commencer à faire du ML propre et efficace.
Mais la vraie révolution, c’est FrankenPHP. Ce serveur PHP nouvelle génération apporte un mode worker ultra-puissant, capable d’exécuter des tâches longues, persistantes et gourmandes en mémoire. Et c’est là que le POC prend tout son sens :
on peut maintenant dédier un worker à l’analyse et au scoring en direct, sans bloquer le reste de l’application Symfony.
Oui, vous avez bien lu : du live scoring en PHP, rendu possible par une gestion fine des threads et de la mémoire. Chaque classe virtuelle devient alors un flux vivant, monitoré en temps réel. Le professeur, depuis son dashboard, peut visualiser la qualité de la session, la participation moyenne, ou encore l’évolution du scoring collectif au fil du cours.
PHP se transforme ici en chef d’orchestre de données intelligentes, coordonnant les flux audio, textuels et analytiques. Ce n’est plus seulement un langage serveur : c’est le cœur battant d’une IA éducative souveraine.
ClassroomAnalysis – le cœur de l’analyse IA en temps réel
Jusqu’ici, on a posé les fondations : le streaming en direct avec LiveKit, la transcription fiable avec Whisper, et l’intelligence analytique de Rubix ML. Il est temps maintenant de rassembler tout cela dans une brique centrale, la pièce maîtresse du système : ClassroomAnalysis.
L’objectif de ce module est limpide : analyser automatiquement la qualité d’une session de classe — qu’elle soit en présentiel ou en ligne — en s’appuyant sur le machine learning, tout en respectant scrupuleusement la vie privée des participants.
Une architecture pensée pour la scalabilité et la transparence
L’entité ClassroomAnalysis agit comme une photo instantanée d’une session analysée. Elle regroupe les scores IA(engagement, participation, qualité de la session), les indicateurs bruts extraits du transcript (nombre d’intervenants, équilibre des temps de parole, nombre de questions, durée du cours, etc.) et les métadonnées utiles (version du modèle ML, date d’analyse, performance du worker).
Le ClassroomAnalysisService, lui, joue le rôle du cerveau de l’opération. Il reçoit les transcripts générés par Whisper, en extrait des features statistiques, entraîne ou recharge un modèle ML — ici un Gradient Boost pour sa capacité à gérer des signaux hétérogènes —, puis prédit les scores et les enregistre.
Le tout fonctionne de manière asynchrone, grâce au composant Messenger de Symfony.
Chaque nouvelle session déclenche un message AnalyzeClassroomMessage, exécuté par un worker dédié (AnalyzeClassroomMessageHandler). Ce worker dispose de ressources étendues en mémoire et en temps d’exécution grâce à FrankenPHP, ce qui permet de traiter plusieurs classes en parallèle sans ralentir le serveur principal.
Du flux audio au scoring final : la boucle d’analyse
- L’audio capté par LiveKit est envoyé au backend.
- Whisper transcrit le flux vocal en texte anonymisé.
- Ce transcript alimente la file d’analyse.
- Le worker lit le contenu, en extrait les features, et prédit les scores via Rubix ML.
- Les résultats sont sauvegardés et affichés en temps réel sur le dashboard enseignant.
Ce flux continu permet une analyse vivante et instantanée : le professeur voit immédiatement le niveau d’engagement global, la participation moyenne, et la qualité perçue de la session.
Exemple concret
Prenons un extrait de transcript :
user_1: Bonjour à tous
user_2: Bonjour professeur
user_1: Aujourd’hui on parle de Symfony ?
user_3: C’est quoi Symfony ?
user_1: Un framework PHP.Résultat de l’analyse :
- 3 intervenants
- 2 étudiants actifs
- 2 questions posées
- 60 % du temps de parole côté professeur
- Scores IA → engagement : 78/100, qualité : 70/100, participation : 67/100
En quelques secondes, la session est transformée en une lecture intelligente du cours.

Les atouts clés du système
Performance et observabilité : logs détaillés, métriques claires, et gestion automatique des erreurs.
Respect total de la vie privée : tous les flux sont anonymisés avant traitement.
Analyse en temps réel : chaque nouvelle prise de parole est intégrée dynamiquement.
Architecture scalable : tout passe par Messenger (workers + files de messages).
Apprentissage continu : le modèle est réentraîné régulièrement avec de nouvelles données.
Apprentissage en continu
<?php
namespace App\Service;
use App\Entity\ClassroomAnalysis;
use App\Entity\ClassroomSession;
use App\Repository\ClassroomAnalysisRepository;
use App\Repository\ClassroomSessionRepository;
use Doctrine\ORM\EntityManagerInterface;
use Psr\Log\LoggerInterface;
use Rubix\ML\Datasets\Labeled;
use Rubix\ML\Datasets\Unlabeled;
use Rubix\ML\Learner;
use Rubix\ML\Regressors\GradientBoost;
use Rubix\ML\Regressors\RegressionTree;
class ClassroomAnalysisService
{
private const MODEL_VERSION = 'v4.0-gradientboost-classroom';
private const MIN_TRAINING_SAMPLES = 5;
private ?Learner $model = null;
private bool $isTrained = false;
public function __construct(
private readonly ClassroomSessionRepository $sessionRepository,
private readonly ClassroomAnalysisRepository $analysisRepository,
private readonly EntityManagerInterface $em,
private readonly LoggerInterface $logger,
private readonly string $transcriptsPath,
private readonly string $modelsPath
) {
// Ensure directories exist
if (!is_dir($this->transcriptsPath)) {
mkdir($this->transcriptsPath, 0755, true);
}
if (!is_dir($this->modelsPath)) {
mkdir($this->modelsPath, 0755, true);
}
}
/**
* Process transcript files in var/transcripts/
* Optionally limit processing to a single session.
*/
public function processTranscripts(?int $sessionId = null, bool $forceAnalysis = false): array
{
$startTime = microtime(true);
$processed = 0;
$errors = [];
try {
// Find all .txt files in transcripts directory
$files = glob($this->transcriptsPath . '/*.txt');
if ($sessionId !== null) {
$targetFile = sprintf('%s/session-%d.txt', $this->transcriptsPath, $sessionId);
$files = file_exists($targetFile) ? [$targetFile] : [];
}
if (empty($files)) {
return [
'success' => true,
'message' => 'No transcript files to process',
'processed' => 0
];
}
foreach ($files as $filePath) {
try {
// Extract session ID from filename: session-{id}.txt
$filename = basename($filePath);
if (!preg_match('/^session-(\d+)\.txt$/', $filename, $matches)) {
$this->logger->warning('Invalid transcript filename format', ['filename' => $filename]);
continue;
}
$sessionIdFromFile = (int) $matches[1];
if ($sessionId !== null && $sessionIdFromFile !== $sessionId) {
continue;
}
// Process transcript
$this->processTranscriptFile($filePath, $sessionIdFromFile, $forceAnalysis);
$processed++;
} catch (\Exception $e) {
$errors[] = [
'file' => basename($filePath),
'error' => $e->getMessage()
];
$this->logger->error('Failed to process transcript', [
'file' => $filePath,
'error' => $e->getMessage()
]);
}
}
$processingTime = round((microtime(true) - $startTime) * 1000);
return [
'success' => true,
'message' => 'Transcripts processed successfully',
'processed' => $processed,
'errors' => count($errors),
'processing_time_ms' => $processingTime
];
} catch (\Exception $e) {
$this->logger->error('Transcript processing failed', [
'error' => $e->getMessage()
]);
return [
'success' => false,
'message' => 'Processing failed: ' . $e->getMessage()
];
}
}
/**
* Process a single transcript file
*/
private function processTranscriptFile(string $filePath, int $sessionId, bool $forceAnalysis = false): void
{
// Load classroom session
$session = $this->sessionRepository->find($sessionId);
if (!$session) {
throw new \Exception("Classroom session {$sessionId} not found");
}
// Read and parse transcript (anonymized)
$transcript = file_get_contents($filePath);
if ($transcript === false) {
throw new \Exception("Failed to read transcript file: {$filePath}");
}
// Extract features from transcript (privacy-safe)
$features = $this->extractFeaturesFromTranscript($transcript, $session);
$analysis = $this->analysisRepository->findByClassroomSession($sessionId) ?? new ClassroomAnalysis();
$isNewAnalysis = $analysis->getId() === null;
$analysis->setClassroomSession($session);
$analysis->setModelVersion(self::MODEL_VERSION);
// Store extracted features
$analysis->setTotalSpeakers($features['total_speakers']);
$analysis->setStudentParticipationRate($features['student_participation_rate']);
$analysis->setTeacherSpeakingPct($features['teacher_speaking_pct']);
$analysis->setQuestionCount($features['question_count']);
$analysis->setTurnTakingCount($features['turn_taking_count']);
$analysis->setAvgResponseTimeSec($features['avg_response_time_sec']);
$analysis->setActiveSpeakingPct($features['active_speaking_pct']);
$analysis->setSpeakingBalanceStd($features['speaking_balance_std']);
$analysis->setSessionDurationSec($features['session_duration_sec']);
// Predict scores using ML (if model is trained)
if ($this->loadModel()) {
$predictionStart = microtime(true);
$scores = $this->predictScores($features);
$analysis->setEngagementScore($scores['engagement']);
$analysis->setQualityScore($scores['quality']);
$analysis->setParticipationScore($scores['participation']);
$predictionTime = round((microtime(true) - $predictionStart) * 1000);
$analysis->setPredictionTimeMs((int) $predictionTime);
}
$analysis->setLastUpdatedAt(new \DateTimeImmutable());
$analysis->setIsLiveAnalysis($this->isSessionActive($session));
if ($isNewAnalysis) {
$this->em->persist($analysis);
}
$this->em->flush();
$this->logger->info('Transcript processed successfully', [
'session_id' => $sessionId,
'speakers' => $features['total_speakers'],
'questions' => $features['question_count']
]);
if (!$this->isSessionActive($session) && file_exists($filePath)) {
unlink($filePath);
}
}
/**
* Extract anonymized features from transcript
* Format expected: "user_42: Hello professor"
*/
private function extractFeaturesFromTranscript(string $transcript, ClassroomSession $session): array
{
$lines = explode("\n", trim($transcript));
$speakers = [];
$teacherId = $session->getTeacher()?->getId();
$questionCount = 0;
$turnTakingCount = 0;
$previousSpeaker = null;
foreach ($lines as $line) {
$line = trim($line);
if (empty($line)) {
continue;
}
// Parse format: "user_42: message content"
if (preg_match('/^user_(\d+):\s*(.+)$/i', $line, $matches)) {
$userId = (int) $matches[1];
$content = $matches[2];
// Track unique speakers
if (!isset($speakers[$userId])) {
$speakers[$userId] = [
'lines' => 0,
'is_teacher' => ($userId === $teacherId)
];
}
$speakers[$userId]['lines']++;
// Count questions
if (str_ends_with($content, '?')) {
$questionCount++;
}
// Count turn-taking (speaker changes)
if ($previousSpeaker !== null && $previousSpeaker !== $userId) {
$turnTakingCount++;
}
$previousSpeaker = $userId;
}
}
// Calculate metrics
$totalSpeakers = count($speakers);
$totalLines = array_sum(array_column($speakers, 'lines'));
$studentCount = $session->getStudents()->count();
// Count how many students actually spoke
$studentsSpokeCount = 0;
$teacherLines = 0;
$speakerLineCounts = [];
foreach ($speakers as $userId => $data) {
$speakerLineCounts[] = $data['lines'];
if ($data['is_teacher']) {
$teacherLines = $data['lines'];
} else {
$studentsSpokeCount++;
}
}
// Calculate participation rate
$studentParticipationRate = $studentCount > 0 ? ($studentsSpokeCount / $studentCount) : 0.0;
// Teacher speaking percentage
$teacherSpeakingPct = $totalLines > 0 ? ($teacherLines / $totalLines) : 0.0;
// Speaking balance (standard deviation of line counts)
$speakingBalanceStd = $this->calculateStdDev($speakerLineCounts);
// Session duration (from session entity)
$sessionDurationSec = 0;
if ($session->getStartAt() && $session->getEndAt()) {
$sessionDurationSec = $session->getEndAt()->getTimestamp() - $session->getStartAt()->getTimestamp();
}
// Active speaking percentage (estimated: lines / total possible lines)
// Assume 1 line = ~10 seconds
$estimatedSpeakingTimeSec = $totalLines * 10;
$activeSpeakingPct = $sessionDurationSec > 0 ? min(1.0, $estimatedSpeakingTimeSec / $sessionDurationSec) : 0.0;
// Average response time (estimated: session time / turn-taking count)
$avgResponseTimeSec = $turnTakingCount > 0 ? ($sessionDurationSec / $turnTakingCount) : 0.0;
return [
'total_speakers' => $totalSpeakers,
'student_participation_rate' => round($studentParticipationRate, 2),
'teacher_speaking_pct' => round($teacherSpeakingPct, 2),
'question_count' => $questionCount,
'turn_taking_count' => $turnTakingCount,
'avg_response_time_sec' => round($avgResponseTimeSec, 1),
'active_speaking_pct' => round($activeSpeakingPct, 2),
'speaking_balance_std' => round($speakingBalanceStd, 2),
'session_duration_sec' => $sessionDurationSec,
];
}
/**
* Calculate standard deviation
*/
private function calculateStdDev(array $values): float
{
if (count($values) < 2) {
return 0.0;
}
$mean = array_sum($values) / count($values);
$variance = 0.0;
foreach ($values as $value) {
$variance += pow($value - $mean, 2);
}
return sqrt($variance / count($values));
}
/**
* Train the GradientBoost model on existing analyses with manual scores
*/
public function train(): array
{
$startTime = microtime(true);
try {
// Fetch analyses with manual scores (for training)
// In the future, teachers will manually rate sessions
$analyses = $this->analysisRepository->createQueryBuilder('ca')
->where('ca.engagementScore IS NOT NULL') // Has manual/predicted scores
->andWhere('ca.totalSpeakers IS NOT NULL') // Has features
->setMaxResults(1000)
->getQuery()
->getResult();
if (count($analyses) < self::MIN_TRAINING_SAMPLES) {
return [
'success' => false,
'message' => sprintf('Not enough training data. Need %d samples, got %d', self::MIN_TRAINING_SAMPLES, count($analyses)),
'samples' => count($analyses)
];
}
// Prepare dataset
$samples = [];
$engagementLabels = [];
$qualityLabels = [];
$participationLabels = [];
foreach ($analyses as $analysis) {
$sample = $this->extractFeaturesForML($analysis);
$samples[] = $sample;
$engagementLabels[] = $analysis->getEngagementScore() ?? 50.0;
$qualityLabels[] = $analysis->getQualityScore() ?? 50.0;
$participationLabels[] = $analysis->getParticipationScore() ?? 50.0;
}
// For simplicity, train on engagement score (can expand to multi-output later)
$dataset = new Labeled($samples, $engagementLabels);
// Create and train GradientBoost model
$this->model = new GradientBoost(
new RegressionTree(5), // Max depth 5
100, // 100 estimators
0.1, // Learning rate
0.8, // Subsample ratio
3 // Min leaf size
);
$this->model->train($dataset);
$this->isTrained = true;
// Save model
$modelPath = $this->getModelPath();
file_put_contents($modelPath, serialize($this->model));
$trainingTime = round((microtime(true) - $startTime) * 1000);
$this->logger->info('Classroom analysis model trained successfully', [
'samples' => count($analyses),
'model_version' => self::MODEL_VERSION,
'training_time_ms' => $trainingTime
]);
return [
'success' => true,
'message' => 'Model trained successfully',
'samples' => count($analyses),
'model_version' => self::MODEL_VERSION,
'training_time_ms' => $trainingTime
];
} catch (\Exception $e) {
$this->logger->error('Classroom analysis training failed', [
'error' => $e->getMessage()
]);
return [
'success' => false,
'message' => 'Training failed: ' . $e->getMessage()
];
}
}
private function isSessionActive(ClassroomSession $session): bool
{
$now = new \DateTimeImmutable();
$startAt = $session->getStartAt();
$endAt = $session->getEndAt();
if ($session->getStatus() === 'open') {
return true;
}
if ($endAt instanceof \DateTimeInterface && $now > \DateTimeImmutable::createFromInterface($endAt)) {
return false;
}
if ($startAt instanceof \DateTimeInterface && $now < \DateTimeImmutable::createFromInterface($startAt)) {
return false;
}
return true;
}
/**
* Predict scores using ML model
*/
private function predictScores(array $features): array
{
if (!$this->isTrained) {
// Default scores if model not trained
return [
'engagement' => 50.0,
'quality' => 50.0,
'participation' => $features['student_participation_rate'] * 100
];
}
// Create feature vector
$featureVector = [
(float) $features['total_speakers'],
(float) $features['student_participation_rate'],
(float) $features['teacher_speaking_pct'],
(float) $features['question_count'],
(float) $features['turn_taking_count'],
(float) $features['avg_response_time_sec'],
(float) $features['active_speaking_pct'],
(float) $features['speaking_balance_std'],
(float) $features['session_duration_sec'],
];
$dataset = new Unlabeled([$featureVector]);
$predictions = $this->model->predict($dataset);
$engagementScore = $predictions[0];
// For now, derive other scores from engagement
// In the future, can train separate models for each
return [
'engagement' => max(0, min(100, $engagementScore)),
'quality' => max(0, min(100, $engagementScore * 0.9)), // Slightly lower
'participation' => max(0, min(100, $features['student_participation_rate'] * 100))
];
}
/**
* Extract features for ML prediction
*/
private function extractFeaturesForML(ClassroomAnalysis $analysis): array
{
return [
(float) ($analysis->getTotalSpeakers() ?? 0),
(float) ($analysis->getStudentParticipationRate() ?? 0.0),
(float) ($analysis->getTeacherSpeakingPct() ?? 0.0),
(float) ($analysis->getQuestionCount() ?? 0),
(float) ($analysis->getTurnTakingCount() ?? 0),
(float) ($analysis->getAvgResponseTimeSec() ?? 0.0),
(float) ($analysis->getActiveSpeakingPct() ?? 0.0),
(float) ($analysis->getSpeakingBalanceStd() ?? 0.0),
(float) ($analysis->getSessionDurationSec() ?? 0),
];
}
/**
* Load trained model from file
*/
private function loadModel(): bool
{
if ($this->isTrained) {
return true;
}
$modelPath = $this->getModelPath();
if (!file_exists($modelPath)) {
return false;
}
try {
$this->model = unserialize(file_get_contents($modelPath));
$this->isTrained = true;
return true;
} catch (\Exception $e) {
$this->logger->error('Failed to load classroom analysis model', ['error' => $e->getMessage()]);
return false;
}
}
private function getModelPath(): string
{
return $this->modelsPath . '/classroom_analysis_model.bin';
}
/**
* Get model info
*/
public function getModelInfo(): array
{
$modelPath = $this->getModelPath();
return [
'model_version' => self::MODEL_VERSION,
'model_exists' => file_exists($modelPath),
'model_path' => $modelPath,
'is_loaded' => $this->isTrained,
'model_size_kb' => file_exists($modelPath) ? round(filesize($modelPath) / 1024, 2) : 0,
'last_modified' => file_exists($modelPath) ? date('Y-m-d H:i:s', filemtime($modelPath)) : null,
'transcripts_path' => $this->transcriptsPath,
];
}
}
Décryptage du service ClassroomAnalysisService
Cette classe est le moteur d’analyse intelligent du système. Elle orchestre toute la chaîne de traitement, depuis la récupération des transcriptions jusqu’à la prédiction des scores IA grâce à Rubix ML.
Étape 1 : lecture et traitement des transcriptions
Le service commence par scanner le dossier var/transcripts/. Chaque fichier correspond à une session (session-12.txt, par exemple) et contient les échanges anonymisés entre le professeur et les élèves.
La méthode processTranscripts() lit ces fichiers, puis appelle processTranscriptFile() pour les transformer en données exploitables.
Étape 2 : extraction des features
C’est ici que l’analyse commence vraiment. La méthode extractFeaturesFromTranscript() découpe chaque ligne du transcript pour identifier :
- le nombre total d’intervenants ;
- le taux de participation des élèves ;
- la proportion de parole du professeur ;
- le nombre de questions posées ;
- la dynamique d’échange (turn-taking) ;
- la durée et l’équilibre global de la session.
Ces indicateurs deviennent ensuite des features numériques, prêtes à être injectées dans le modèle de machine learning.
Étape 3 : prédiction via Rubix ML
Une fois les features extraites, le service charge (ou entraîne) un modèle Gradient Boost basé sur des arbres de régression (RegressionTree).
Ce modèle apprend à prédire trois scores clés :
- Engagement — l’attention et l’implication globale de la classe,
- Qualité — la clarté et la fluidité de la session,
- Participation — le niveau d’interaction collectif.
Si aucun modèle n’est encore entraîné, le service applique des valeurs par défaut, histoire de toujours produire un résultat cohérent.
Étape 4 : apprentissage du modèle
La méthode train() utilise les analyses précédentes pour améliorer le modèle au fil du temps. Chaque nouvelle session évaluée enrichit la base d’apprentissage.
C’est ce qu’on appelle un apprentissage incrémental : la plateforme s’améliore à chaque cours.
Étape 5 : persistance et logs
Les résultats finaux (scores + features) sont sauvegardés dans la base via Doctrine. Les logs détaillent tout : temps de traitement, erreurs éventuelles, sessions analysées.
Le tout est pensé pour être asynchrone, grâce à Messenger et aux workers FrankenPHP. Cela permet de traiter plusieurs classes simultanément sans ralentir le serveur.

En résumé
Le ClassroomAnalysisService agit comme un chef d’orchestre IA :
- Il lit les conversations,
- En extrait les signaux utiles,
- Entraîne un modèle de machine learning,
- Prédit des scores en temps réel,
- Et met tout ça à disposition du tableau de bord enseignant.
Grâce à cette brique, Symfony devient capable de comprendre une classe virtuelle, pas seulement de la diffuser.
Une évolution possible : la capture audio côté serveur avec LiveKit Egress
Aujourd’hui, le système capture le son directement dans le navigateur, via la MediaRecorder API, qui enregistre l’audio mixé de la salle LiveKit avant de l’envoyer par chunks de 60 secondes vers Whisper pour transcription.
Ce fonctionnement a l’avantage d’être simple à mettre en place — pas de dépendances côté serveur, tout passe par le client. Mais il présente aussi quelques limites :
- il consomme les ressources locales de l’élève ou du professeur ;
- il dépend de la stabilité du réseau ;
- et il peut introduire de légères latences ou pertes de données en cas de mauvaise connexion.
LiveKit propose cependant une alternative beaucoup plus robuste : l’API Egress.
Cette fonctionnalité permet de capturer directement l’audio (et la vidéo) sur le serveur LiveKit, sans passer par le navigateur.
Le flux est alors enregistré, traité et transmis à Whisper côté serveur, ce qui garantit :
- une meilleure fiabilité des enregistrements,
- une qualité sonore constante,
- et une réduction notable de la charge client et du trafic réseau.
L’intégration de cette API ouvrirait la voie à une captation temps réel plus professionnelle, idéale pour une version V5 scalable et stable, où l’analyse Whisper pourrait tourner en continu, sans dépendre du matériel utilisateur.
Conclusion
Comme on l’a vu, cette V4 marque un tournant : on est passé d’une simple démonstration à une analyse avancée et automatisée de la salle de classe, tout en respectant scrupuleusement le RGPD. L’ensemble du système est hébergé localement, y compris Whisper, ce qui en fait une solution totalement souveraine.
Nous avons désormais une véritable classe virtuelle augmentée, propulsée par FrankenPHP et bâtie sur l’écosystème Symfony :
- Symfony Messenger pour le traitement asynchrone et les workers,
- Symfony Scheduler pour la réanalyse périodique,
- Symfony UX & Stimulus pour la couche front réactive,
- et Mercure pour la diffusion en temps réel des scores et des événements de classe.
Pour la partie visioconférence “façon Google Meet”, nous nous appuyons sur l’excellent LiveKit, une brique open source solide — la même utilisée par OpenAI pour son mode vocal.
Bien sûr, tout n’est pas parfait : ce POC reste un terrain d’expérimentation, mais il démontre qu’on peut construire, avec des outils libres et modernes, une plateforme d’analyse pédagogique intelligente, souveraine et évolutive.
La suite logique ? Explorer des pistes plus ambitieuses : pourquoi ne pas connecter PGVector pour stocker et interroger des embeddings de sessions ? Ou affiner le modèle Rubix ML avec un apprentissage multi-sorties pour une évaluation plus fine ?
Ce n’est qu’un début. Le vrai pouvoir du POC, c’est justement d’être vivant, itératif et perfectible. On teste, on casse, on comprend, on recommence. C’est ça, la beauté du code incrémental : à chaque itération, la machine devient un peu plus intelligente — et nous aussi.
Laisser un commentaire